
Your KV cache exists.
We make it better.
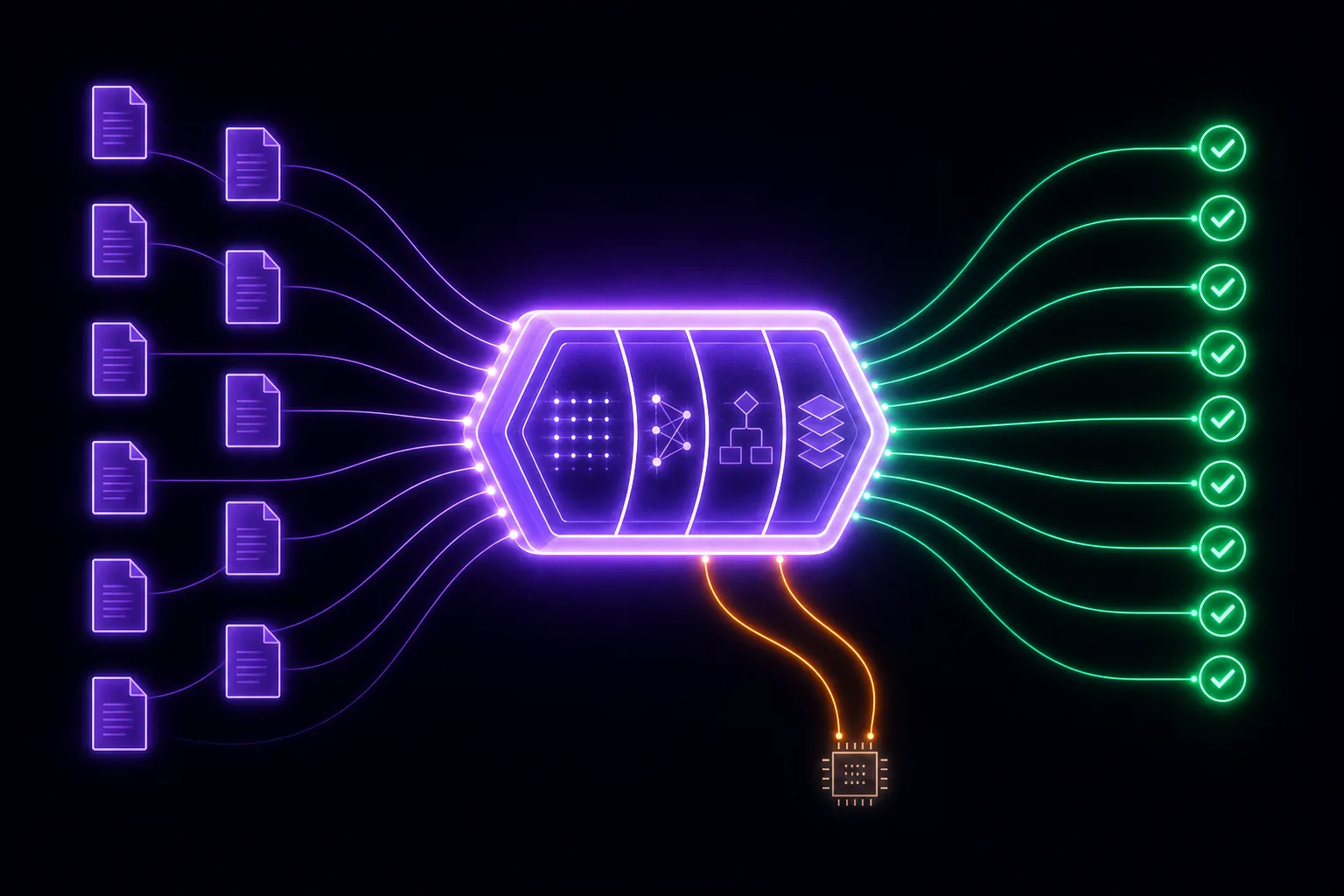
Every major inference server ships with KV cache. But default caching leaves most of that capacity on the table. HyperRAG is a drop-in optimization layer that makes your existing cache capture far more hits, automatically, from the first request.
Cache hit rate
94.2%
up to
6x faster
Slots into

The problem
Your cache is working. Just not hard enough.
Every major inference server ships with built-in KV cache. But the default implementation doesn't recognize when queries share the same documents, doesn't know which cached entries are worth keeping, and doesn't prevent the model from sitting idle while retrieval runs. Your GPU ends up reprocessing context it has already seen.
Duplicate work on every request: when different users reference the same documents, each request rebuilds that context from scratch. The overlap goes unrecognized and you pay for the same compute repeatedly.
The cache drops what matters most: entries are evicted by recency, not by how often they are reused. At peak load, your most-requested context is the first to go, forcing expensive recomputes exactly when you can least afford them.
Generation stalls waiting on retrieval: the model sits idle until documents are fetched, even when shared context is already in the cache and ready to use. Latency compounds at scale.
How it works
Smarter decisions on every request.
HyperRAG sits in front of your inference API. It identifies shared document context across incoming requests and routes them to cached computation your framework already has, rather than reprocessing the same context from scratch each time.

What you get
More from the cache you already have.
Cache hits compound: repeated document context is recognized and reused across concurrent requests, not just sequential ones.
Popular entries stay resident: smarter eviction keeps the context your users hit most in memory when traffic spikes.
Generation starts sooner: prefill overlap cuts time-to-first-token. Your GPU stops idling while retrieval finishes.
Works across every RAG workload.
High-volume APIs
Shared document context across thousands of requests per minute. HyperRAG turns overlap into speedup.
Enterprise search
Internal queries return to the same pages repeatedly. Popular content stays fast as traffic scales.
Agentic workflows
Multi-step agents revisit documents across reasoning steps. Each revisit hits the cache, cutting cumulative latency.
Long-context inference
Similar long prompts share substantial context. HyperRAG reuses cached computation and cuts prefill cost.
Model support
Built for production models.
Works with popular open-weight model families out of the box, from 1B to 405B. Custom models and private deployments are supported. HyperRAG's cache optimization is model-agnostic: it works at the serving layer, not inside the model.
On top of your stack. Not instead of it.
HyperRAG mounts in front of your existing inference API. No configuration, no cluster changes. Start getting cache hits on the first query.
No model changes. No migration. No cluster reconfiguration.
Smarter caching starts on the first query. Gains visible immediately.
from hyperrag import HyperRAG hr = HyperRAG() ctrl = hr.deploy() # Query as usual - HyperRAG optimizes automatically r = ctrl.query( text="What is transformer attention?", doc_ids=["d1", "d2"], ) # Metrics available from first request print(r.latency_ms, "ms") print(ctrl.metrics())
Up to 6x faster, measured.
1,000 queries per model across four RAG workload patterns. Tested on 14 production models from 2B to 120B parameters.
Models testedTested
14
Avg TTFT reductionAvg TTFT
54%
Avg throughput gainThroughput
2.4×
HyperRAG vs. baseline · latency in ms (lower is better)
High-volume
5.76×
9.8ms vs 56.4ms
Long docs
5.46×
10.4ms vs 56.8ms
Multi-step
5.49×
10.4ms vs 57.1ms
Complex pipes
6.27×
9.1ms vs 57.1ms
4 representative models shown. Averages computed across all 14 tested models. Results will vary by workload and hardware.
Your stack stays. Your latency drops.
HyperRAG is available now on PyPI. Drop it in front of your inference API and start seeing the difference immediately.